16: Readiness Probe a Service
Wpływ Readiness Probe na Service
Cel zadania
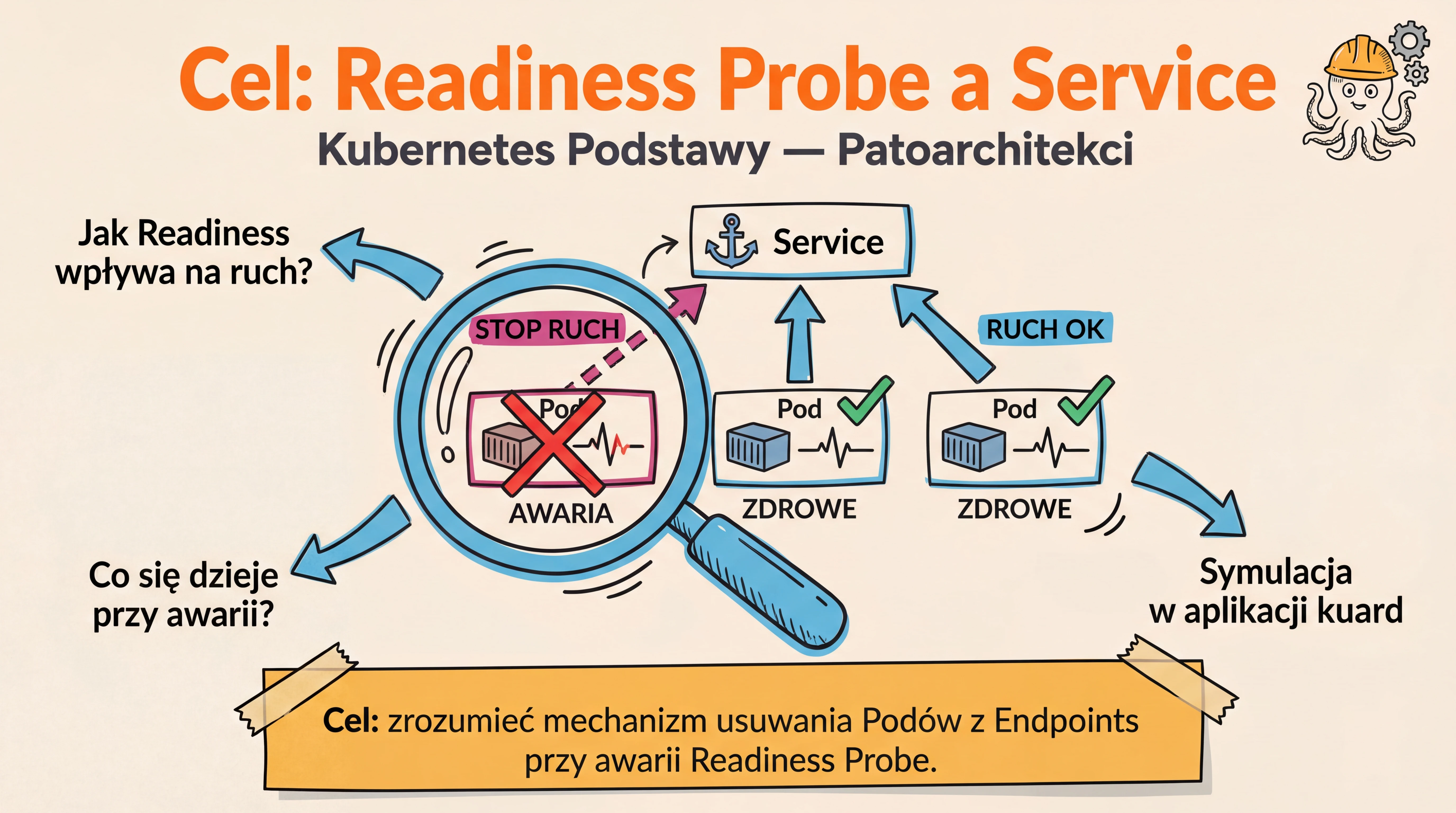 Zrozumienie jak Readiness Probe wpływa na dostępność podów w Service poprzez symulację awarii w aplikacji kuard.
Zrozumienie jak Readiness Probe wpływa na dostępność podów w Service poprzez symulację awarii w aplikacji kuard.
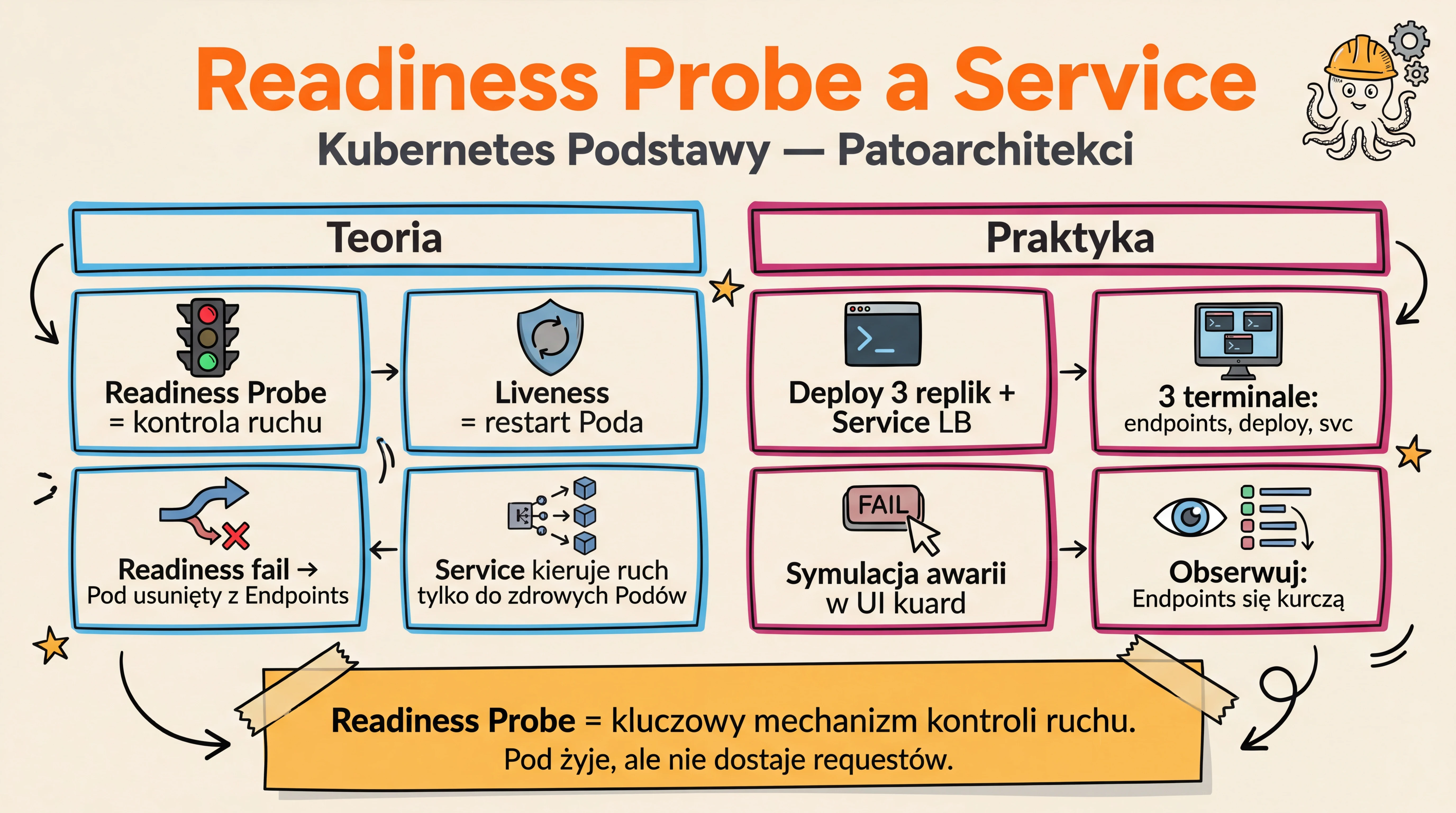
Teoria
Dlaczego Readiness wpływa na Service?
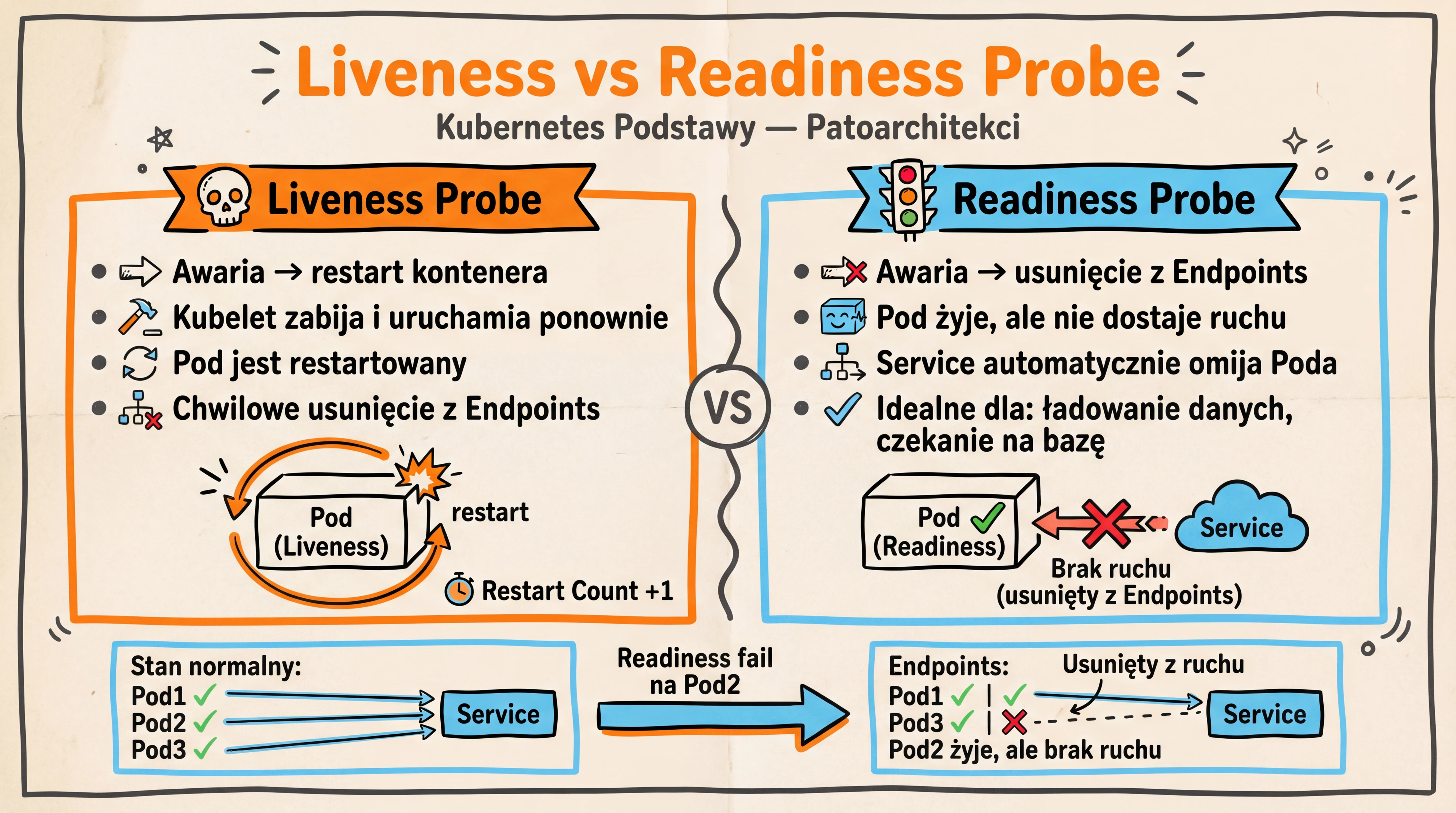
- Liveness Probe → awaria = restart Poda (kubelet zabija i uruchamia ponownie)
- Readiness Probe → awaria = usunięcie z Endpoints (Pod żyje, ale nie dostaje ruchu)
- Service kieruje ruch tylko do Podów, które przechodzą readiness check
- To oznacza: jeśli Twoja aplikacja nie jest gotowa (np. ładuje dane, czeka na bazę) — Service automatycznie omija ten Pod
Diagram: Co się dzieje przy readiness failure
graph TD
SVC["Service: kuard-service"]
subgraph BEFORE["Stan normalny"]
EP1["Endpoints:<br/>Pod1 ✅ Pod2 ✅ Pod3 ✅"]
end
subgraph FAIL["Po readiness failure na Pod2"]
EP2["Endpoints:<br/>Pod1 ✅ Pod3 ✅"]
POD2["Pod2 — działa, ale<br/>usunięty z Endpoints<br/>(nie dostaje ruchu)"]
end
SVC --> BEFORE
BEFORE -->|"Readiness fail na Pod2"| FAIL
style SVC fill:#e3f2fd,stroke:#1976d2
style POD2 fill:#fff3e0,stroke:#ff9800
style EP1 fill:#e8f5e9
style EP2 fill:#e8f5e9
Różnica Liveness vs Readiness w kontekście Service
| Sonda | Przy awarii | Wpływ na Service | Pod żyje? |
|---|---|---|---|
| Liveness | Restart kontenera | Chwilowe usunięcie z Endpoints (bo restart) | Restartowany |
| Readiness | Usunięcie z Endpoints | Service omija tego Poda | Tak, nadal działa |
Zadanie: Testowanie wpływu Readiness na Service
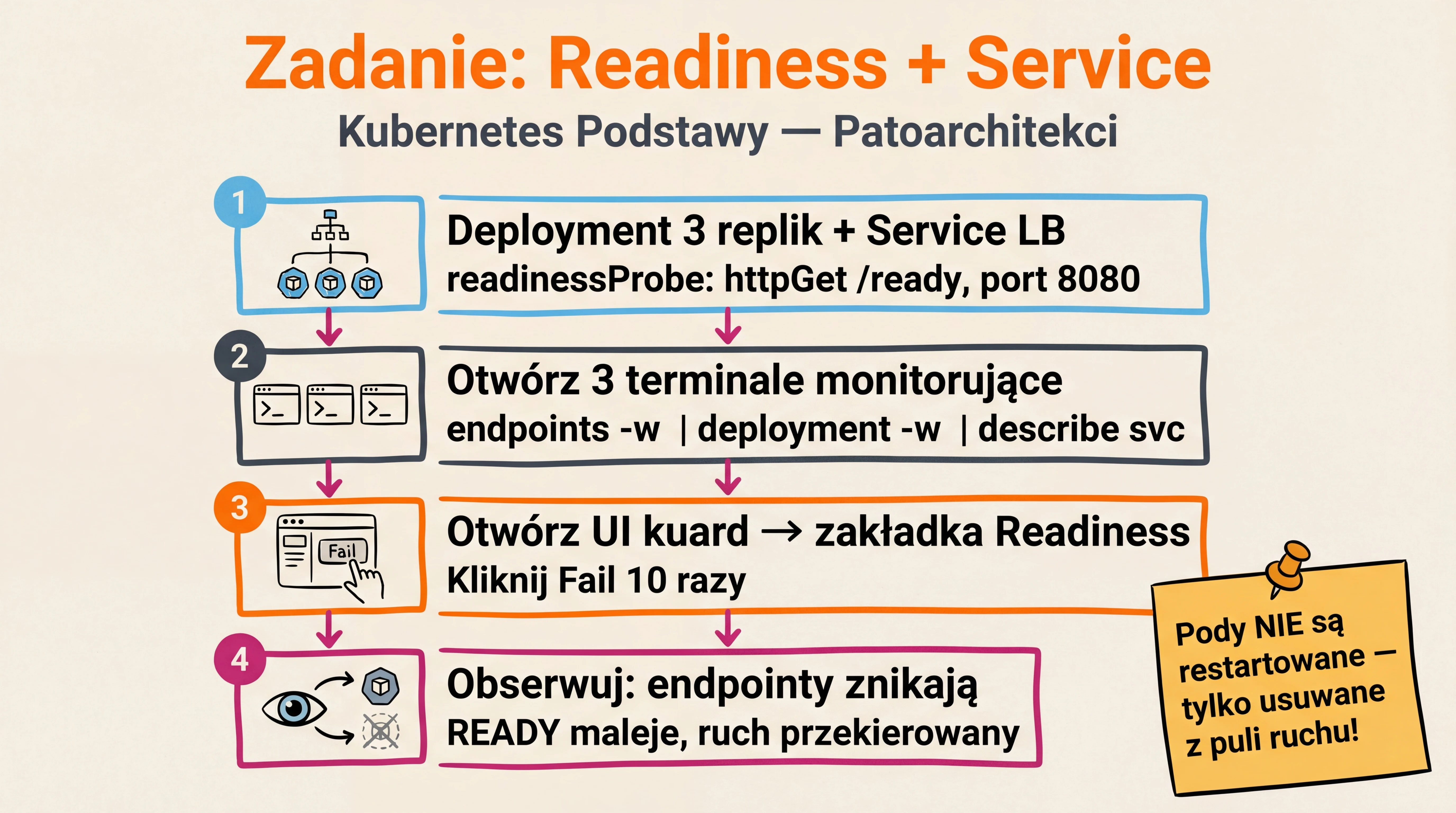
Krok 1: Deployment i Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: kuard-deployment
spec:
replicas: 3
selector:
matchLabels:
app: kuard
template:
metadata:
labels:
app: kuard
spec:
containers:
- name: kuard
image: <ACR_NAME>.azurecr.io/kuard:1
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 2
periodSeconds: 10 # Sprawdzanie co 10 sekund
failureThreshold: 3
---
apiVersion: v1
kind: Service
metadata:
name: kuard-service
spec:
type: LoadBalancer
selector:
app: kuard
ports:
- protocol: TCP
port: 80
targetPort: 8080
Krok 2: Wdrożenie i Przygotowanie
- Utwórz zasoby:
kubectl apply -f kuard-deployment.yaml - Poczekaj na przydzielenie zewnętrznego IP:
kubectl get service kuard-service -w
Krok 3: Monitorowanie w osobnych terminalach
Terminal 1 - Monitorowanie endpointów:
kubectl get endpoints kuard-service -w
Terminal 2 - Monitorowanie deploymentu:
kubectl get deployment kuard-deployment -w
Terminal 3 - Szczegóły serwisu:
watch -n 1 kubectl describe service kuard-service
Krok 4: Symulacja awarii
- Otwórz UI kuard w przeglądarce używając zewnętrznego IP serwisu (port 80)
- Przejdź do zakładki “Readiness Probe”
- Kliknij przycisk “Fail” 10 razy
- Obserwuj zmiany w każdym z terminali monitorujących
Co obserwować:
- W terminalu endpointów:
- Stopniowe usuwanie adresów IP podów z puli endpointów
- Zmniejszenie liczby dostępnych endpointów
- W terminalu deploymentu:
- Zmiana liczby dostępnych (READY) podów
- Status READY powinien się zmniejszać
- W terminalu serwisu:
- Zmiany w sekcji Endpoints
- Aktualizacje w Events
Ważne obserwacje
- Zachowanie podów:
- Pody nie są restartowane
- Pozostają uruchomione, ale są usuwane z puli ruchu
- Zachowanie serwisu:
- Ruch jest kierowany tylko do zdrowych podów
- Load balancing działa tylko na podach z pozytywnym wynikiem readiness
- Wpływ na aplikację:
- Użytkownicy nie widzą błędów
- Ruch jest automatycznie przekierowywany do działających instancji
Wnioski
- Readiness Probe jest kluczowym mechanizmem kontroli ruchu
- Pozwala na bezpieczne usuwanie podów z puli ruchu bez ich zatrzymywania
- Zapewnia wysoką dostępność aplikacji podczas problemów z pojedynczymi instancjami
Przywracanie normalnego stanu
- W UI kuard kliknij “Clear” na stronie Readiness Probe
- Obserwuj jak pody wracają do puli endpointów
- Zwróć uwagę na czas potrzebny do uznania poda za zdrowy (successThreshold)